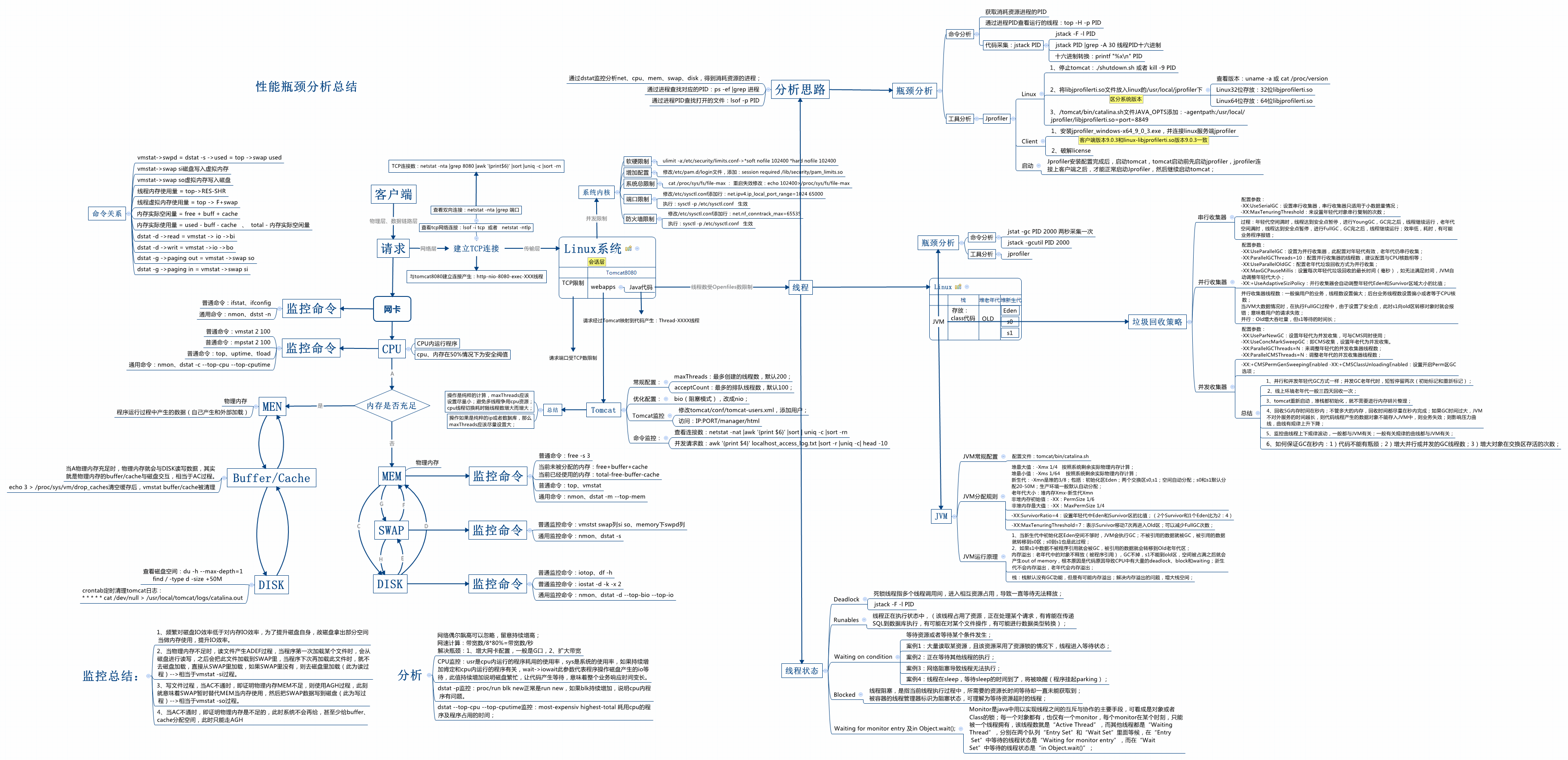
介绍
性能分析,其实就是找出应用或系统的瓶颈,并设法去避免或者缓解它们,从而更高效地利用系统资源处理更多的请求,这包括以下几个步骤:
1、为应用程序和系统设置性能目标
2、进行性能基准测试
3、性能分析和定位
4、优化系统和应用程序
5、性能监控和告警
工欲善其事,必先利其器。性能领域大师 Brendan Gregg 描绘的性能工具图谱:
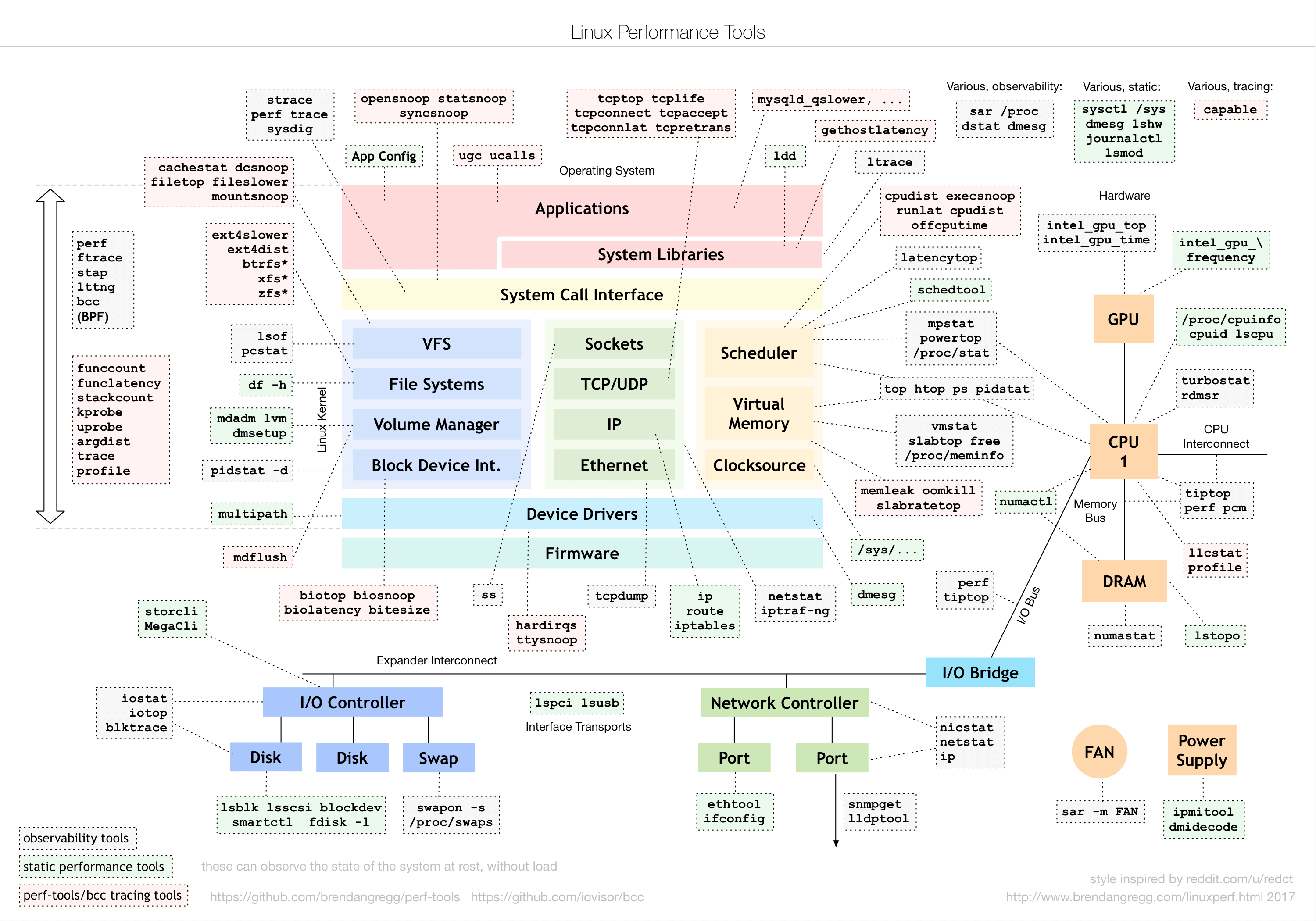
本文主要介绍了性能问题的通用分析方法,几乎可以排查任意代码语言的应用程序的性能问题,对于适用于特定语言的特定问题的排查工具,本文未介绍。
CPU 性能
平均负载
平均负载可通过执行 top 或 uptime 命令查看,load average 后面的 3 个数字依次是系统过去 1 分钟、5 分钟、15分钟的平均负载。
怎么理解平均负载
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数。所谓可运行状态的进程是指处于 R 状态(Running 或 Runnable)的进程;不可中断状态的进程是指处于 D 状态的进程。
如果平均负载为 2,那意味着:
·在 2 核 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用
·在 4 核 CPU 的系统上,意味着 CPU 有 50% 的是空闲的
·在 1 核 CPU 的系统上,意味着有一半的进程竞争不到 CPU
平均负载多少合理
如果在 1 核 CPU 的系统上,通过命令查看平均负载的 3 个数值是 1.88, 0.88, 5.88,那就说明在过去 1 分钟内,系统有 88% 的超载,而在过去的 15 分钟内,系统有 488% 的超载,从整体趋势来看,系统的负载是在降低的。
一般来说,当平均负载超过 CPU 数量的 70% 时,就需要排查负载高的原因了。70% 不是绝对的,推荐做法是把平均负载监控起来,根据历史数据来判断负载变化趋势,如果负载明显升高,则需要去排查问题。
平均负载和CPU使用率
平均负载和 CPU 使用率变化并不完全一致:
·CPU 密集型进程,大量使用 CPU 会导致平均负载升高,此时两者变化是一致的
·I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定高
·大量等待 CPU 的进程调度也会导致平均负载升高,此时 CPU 使用率也会变高
CPU上下文切换
进程在竞争 CPU 时并没有真正的运行,为什么还会导致系统负载升高?可能的原因之一是CPU 上下文切换,根据一些测试报告,CPU 进行一次上下文切换需要消耗几十纳秒到几微秒的 CPU 时间,如果上下文切换比较多的情况下,CPU 将会花费大量时间用于切换上下文,缩短了真正运行进程的时间,这是导致负载升高的一个重要因素。
CPU 在进行上下文切换时,CPU 的主要工作是保存当前任务的 CPU 寄存器和程序计数器,然后加载下一个任务的 CPU 寄存器和程序计数器。根据不同的场景,CPU 上下文切换可分为进程上下文切换、线程上下文切换和中断上下文切换。
查询CPU上下文切换
使用 vmstat 命令查看 CPU 上下文切换和中断的数据
# 每秒输出一组数据
$ vmstat 1
procs --memory-- -swap- --io-- -system-- --cpu--
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 132448 95884 82524 355236 0 0 1 3 24 4 1 0 99 0 0r(Running or Runnable)是就绪队列的长度。如果该值大于 CPU 核数,则有进程在竞争 CPU。
b(Blocked)是处于不可中断状态的进程数
cs(context switch)是每秒上下文切换次数
in(interrupt)是每秒中断的次数
查看进程的上下文切换数据
$ pidstat -w -u 1
Linux 4.18.0-348.7.1.el8_5.x86_64 (centos) 08/03/2024 _x86_64_ (2 CPU)
06:12:00 PM UID PID cswch/s nvcswch/s Command
06:12:01 PM 0 11 36.27 0.00 rcu_sched
06:12:01 PM 0 24952 10.78 0.00 redis-server
06:12:01 PM 0 32128 0.98 0.00 kworker/0:1-eventscswch 是自愿上下文切换,是指进程因无法获取所需资源而导致的上下文切换。nvcswch 是非自愿上下文切换,是指进程由于 CPU 时间片到了等原因,被系统强制调度而发生的上下文切换。
如果查看进程的上下文切换,发现上下文切换数量不高,那么可以查看线程的上下文切换,使用命令是
pidstat -wt 1查看发生了什么类型的中断,
watch -d cat /proc/interrupts上下文切换问题分析
每秒上下文切换的次数和 CPU 的性能有关,一般情况下,上下文切换次数超过一万次,或者切换次数出现数量级增长,系统很可能已经出现了性能问题。
·自愿上下文切换多,说明进程都在等待资源,可能发生了 I/O 问题;
·非自愿上下文切换多,说明进程都在被强制调度,也就是进程都在争抢 CPU,CPU 成了瓶颈;
·中断次数多了,说明 CPU 主要在处理中断,通过查看 /proc/interrupts 分析具体的中断类型;
CPU使用率
我们常看到的 CPU 使用率是平均 CPU 使用率,是一些工具或命令每隔一段时间获取一次数据,作差后计算出这段时间的平均 CPU 使用率。计算公式:
平均CPU使用率 = 1 - (Δ空闲时间 / Δ总CPU时间)常用的查询 CPU 使用率的工具:
mpstat:CPU 性能分析工具,实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
pidstat:进程性能分析工具,实时查看进程的 CPU、内存、I/O、上下文切换等性能指标。
应用CPU使用率过高
通过 top、ps、pidstat 等工具很容易找到 CPU 使用率高的进程和线程。对于 Java 应用,我们一般通过以下步骤定位问题:
1、通过 top 命令找到进程 PID,通过 top -Hp PID 命令查看该进程下的线程,找到占用 CPU 的线程 PID;
2、将线程 PID 转成 16 进制,printf '%x\n' 线程 PID
3、分析问题,jstack 进程PID | grep 线程16进制 -A 30
4、通过堆栈中的信息,可以直接定位到代码中的出现问题的具体位置
但如果不是 Java 应用呢?下面是一种通用的方法——使用 perf 工具可以分析 CPU 性能:
$ perf top
Samples: 8K of event 'cycles', 3000 Hz, Event count (approx.): 728643798 lost: 0/0 drop: 0/0
Overhead Shared Object Symbol
2.07% [kernel] [k] find_get_entry
1.50% libpython3.11.so.1.0 [.] _PyEval_EvalFrameDefault
0.96% perf [.] dso__find_symbol
0.86% [kernel] [k] __sched_text_star第一行数据是 perf 共采集了 8K 个 CPU 周期,总事件数为 728643798。列表中一共 4 列,分别是:
·Overhead:该 Symbol 事件在所有采样中的比例
·Shared:该函数或者指令所在的动态共享对象,如内核、进程名、动态链接库名、内核模块名 等
·Object:动态共享对象的类型,[.] 表示用户空间的可执行程序或者动态链接库,[k] 表示内核空间
·Symbol:函数名,当函数名未知时,用 16 进制的地址来表示
如果需要显示函数调用关系,那么需要执行这个命令 perf top -g -p pid,然后按方向键选择查看对应函数的调用关系。例如:执行如下 python 代码:
result = 1
while True:
result *= 11通过 perf top -g -p pid 命令查看的结果如下图,mul 函数的 CPU 使用率最高,和代码里存在的问题是一样的。
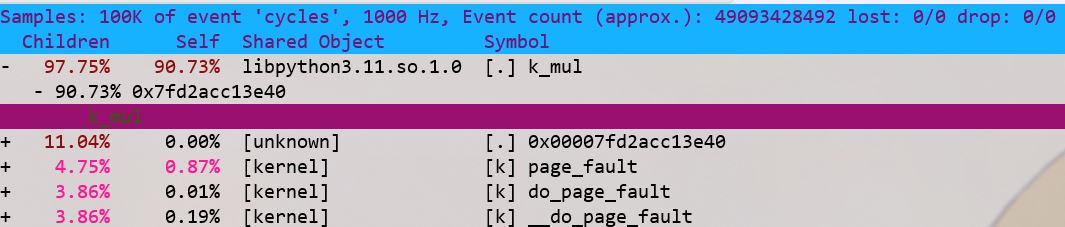
这里解释一下 Children 和 Self 的含义,可通过 man perf-report 命令查看工具手册,简单来说:
·Self 是最后一列的符号(可以理解为函数)本身所占比例;
·Children 是这个符号调用其他符号(可以理解为子函数,包括直接和间接调用)占用的比例之和。
若出现无法解释的 CPU 使用率高的情况,那么可以考虑是否存在短时应用,一般有如下 2 中情况:
1、应用里直接调用了其他二进制程序,这些程序运行时间短,很难通过 top 命令发现;
2、应用本身在不停的崩溃重启,启动过程的资源初始化,可能会占用较多的 CPU;
对于这类进程,可以使用 pstree 或者 execsnoop 找到它们的父进程,从父进程入手排查问题。
iowait
iowait 高不一定代表 I/O 有性能瓶颈。一般提到 iowait 升高,首先会想到是磁盘I/O,可通过命令 iostat -x -m 1 2 查询服务器所有磁盘的 I/O 情况。如果发现磁盘 I/O 很高,那么就需要使用 top 命令查看哪些进程处于 D 状态,然后用 pidstat -d -p pid 1 3 命令查看进程的 I/O 数据。
一般情况到这里已经可以发现问题了,如果想知道应用到底在执行什么 I/O 操作,那就需要查看系统的进程调用,可使用 strace -p pid 命令。
如果上面步骤还找不出来问题,那么进程可能已经是僵尸进程了,可通过 top 或者 ps aux |grep pid 命令查看进程的状态。如果出现僵尸进程,需要找到父进程,可通过 pstree -aps pid命令查找,然后在代码里查找子进程结束的处理是否正确。
如果还是找不出来问题,那么就需要基于事件记录的动态追踪工具了,还是使用 perf top 命令了。
中断
中断是什么
Linux 为了解决中断处理程序执行过长和中断丢失问题,将中断处理过程分为两个阶段,分别是上半部和下半部
·上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作,就是常说的硬中断。
·下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行,就是常说的软中断。
以网卡接收数据包为例:网卡接收到数据包后,会通过硬件中断的方式通知内核新的数据到了,上半部和下半部分别负责的工作是:
·上半部就是把网卡的数据读到内存,然后更新硬件寄存器的状态(表示数据已读完),最后发送一个软中断的信号,通知下半部做进一步处理。
·下半部被软中断信号唤醒,从内存中读取数据,然后按照网络协议栈,对数据进行逐层解析和处理,直到把数据送到应用程序。
查看中断
查看软中断的运行情况cat /proc/softirqs,查看硬中断的运行情况cat /proc/interrupts。查看软中断的输出结果,可以看到各种类型的软中断在不同 CPU 上的累积运行次数:
$ cat /proc/softirqs
CPU0 CPU1
HI: 0 0
TIMER: 16123954 15249385
NET_TX: 1 0
NET_RX: 4197945 2727293
BLOCK: 174780 162562
IRQ_POLL: 0 0
TASKLET: 55285 76987
SCHED: 24546262 22247964
HRTIMER: 3055 1435
RCU: 21638913 20773231第一列是软中断类型。正常情况下,同一种类型的软中断在不同的 CPU 上分布是差不多的,除了 TASKLET 软中断,每个 TASKLET 只运行一次就结束,并且只在调用它的函数所在的 CPU 上运行。
软中断是以内核线程的方式运行的,可通过 ps aux|grep softirq 命令查看这些线程运行情况。
如何使用 perf 工具
一般使用 perf top、perf top -g -p pid、perf record、perf report 等命令就够了。但是在分析 Docker 容器应用时,可能会出现 perf 找不到待分析进程依赖的库,因为容器应用依赖的库都在镜像里面。可以有以下 2 个方法:
1、指定符号路径为容器文件系统的路径:
$ mkdir /tmp/foo
$ bindfs /proc/$PID/root /tmp/foo
$ perf report --symfs /tmp/foo
$ umount /tmp/foo # 解除绑定2、在容器外把分析记录保存下来,再去容器里查看结果:
$ perf record -g -p pid
$ docker cp perf.data image:/tmp
$ docker exec -i -t image bash
$ perf report怎么分析 Java 应用
像 Java 这种通过 JVM 来运行的应用程序,运行堆栈用的都是 JVM 内置的函数和堆栈管理。perf_events 实际上已经支持 JIT,但还需要一个 /tmp/perf-PID.map 文件来进行符号翻译,开源项目 perf-map-agent 可以帮助生成这个符号表。为了生成全部的调用栈,还需要开启 JDK 的选项 -XX:+PreserveFramePointer。
对于 Java 应用程序的问题排查,还可以用 async-profiler 和 arthas 工具。
内核线程CPU高分析
在 Linux 启动过程中,有三个特殊的进程,也就是 PID 最小的三个进程:
·0 号进程为 idle 进程,这是系统创建的第一个进程,它在初始化 1 号和 2 号进程后,变成为空闲任务。当 CPU 上没有其他任务执行时,就会运行它。
·1 号进程为 init 进程,通常是 systemd 进程,在用户态运行,用来管理其他用户态进程。
·2 号进程为 kthreadd 进程,在内核态运行,用来管理内核线程。
故,要查找内核线程,只需要从 2 号进程开始,查它的子孙进程即可:
$ ps -f --ppid 2 -p 2
UID PID PPID C STIME TTY TIME CMD
root 2 0 0 Jul26 ? 00:00:00 [kthreadd]
root 3 2 0 Jul26 ? 00:00:00 [rcu_gp]
root 14 2 0 Jul26 ? 00:00:00 [cpuhp/0]
root 15 2 0 Jul26 ? 00:00:00 [cpuhp/1]
root 18 2 0 Jul26 ? 00:00:05 [ksoftirqd/1]在性能分析中经常用到的内核线程如下:
·ksoftirqd:用于处理软中断,每个 CPU 都有一个
·kswapd0:用于内存回收
·kworker:用于执行内核工作队列,分为绑定 CPU(名称格式为 kworker/CPU:ID)和未绑定 CPU(kworker/uPOOL:ID)两类
·migration:在负载均衡过程中,把进程迁移到 CPU 上。每个 CPU 都有一个 migration 内核线程
·jbd2/sda1-8:用来为文件系统提供日志功能,以保证数据的完整性;名称中的 sda1-8 表示磁盘分区名称和设备号
·pdflush:用于将内存中的脏页(被修改过但未写入磁盘的文件页)写入磁盘(在 3.10 版本后合并到 kworker 中)
怎么查看内核线程在执行什么逻辑呢?适用于普通进程的工具并不适合内核线程,但可以使用 perf 工具。
执行命令 perf record -a -g -p pid -- sleep 30,命名执行结束后,继续执行 perf report 命令,就可以得到线程调用关系图。
为了更友好的查看 perf 结果,可以把结果转成火焰图,可以使用这个工具。火焰图的横轴表示采样数和采样比例,一个函数占用的横轴越宽,代表它执行时间越长;纵轴表示调用栈,由下往上根据调用关系逐个展开,下面的函数是上面函数的父函数,纵轴越高调用栈越深。
内存性能
Linux 内存
我们常说的内存是物理内存,Linux 内核会给每个进程都提供一个独立的虚拟地址空间,并且这个地址空间是连续的,这样进程就可以很方便地访问内存,更确切地说是访问虚拟内存。虚拟内存要比物理内存大很多,只有那些实际使用的虚拟内存才会分配物理内存,是通过内存映射来管理的,就是将虚拟内存地址映射到物理内存地址。为了完成映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系。
内存分配与回收
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()。
对小块内存(小于 128K),使用 brk() 来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。
对大块内存(大于 128K),使用 mmap() 来分配,也就是在文件映射段找一块空闲的内存分配出去。这些内存释放后会直接归还给系统。
当应用程序用完内存后,还需要调用 free() 或 unmap() 来释放这些不用的内存。
系统不会任由某个进程用完所有内存,在内存紧张时,系统会通过一系列机制来回收内存,比如下面这三种方式:
·回收缓存,比如使用 LRU 算法回收最近使用最少的内存页面;
·回收不常访问的内存,把不常用的内存通过交换分区直接写入到磁盘中;
·杀死进程,通过 OOM 直接杀死占用大量内存的进程。
其中 OOM,是内核的一种保护机制,它监控进程的内存使用情况,并使用 oom_score 为每个进程的内存使用情况进行评分,进程的 oom_score 越大,代表内存消耗的越多,也就越容易被 OOM 杀死。
·进程消耗的内存越大,oom_score 就越大
·进程占用的 CPU 越多,oom_score 就越小
当然,也可以通过 /proc 文件系统,手动设置进程的 oom_adj(在较新版本的 Linux 中使用 oom_score_adj),从而调整进程的 oom_score。oom_adj 的范围是 [-17, 15](oom_score_adj 的范围是 [-1000, 1000]),数值越大表示进程越容易被 OOM 杀死,其中 -17 表示禁止 OOM。可通过下面的命令调整进程的 oom_adj 的值:
echo 0 > /proc/PID/oom_adj想知道哪些进程被 OOM 杀死,可执行这个命令 dmesg | grep -i "Out of memory"。
Buffer 和 Cache
Buffer 是缓冲区,Cache 是缓存,两者都是数据在内存中的临时存储,那么它们有什么区别?
·Buffer 是内核缓存区用到的内存,是对原始磁盘块的临时存储,也就是用来缓存读写磁盘的数据,通常不会特别大(20MB 左右),对应的是 /proc/meminfo 中的 Buffers 的值。
·Cache 是内核页缓存和 Slab 用到的内存,是从磁盘读取文件的页缓存,也就是用来缓存读写文件的数据,对应的是 /proc/meminfo 中的 Cached 与 SReclaimable 之和。
进一步解释:我们通常说的“文件”,一般指普通文件,而磁盘或者分区,则指的是块设备文件。在读写普通文件时,I/O 请求会首先经过文件系统,然后由文件系统负责与磁盘进行交互。而在读写块设备文件时,是直接与磁盘交互。这两种读写方式使用的缓存自然不同,文件系统管理的缓存就是 Cache 的一部分,而直接与磁盘交互用的是 Buffer。
缓存命中率
查看 Linux 系统缓存命中情况的命令是 cachestat 和 cachetop,使用这两个命令需要安装 bcc 软件包。
cachestat 查看整个系统的缓存读写命中情况:
$ cachestat 1 3
HITS MISSES DIRTIES HITRATIO BUFFERS_MB CACHED_MB
0 0 3 0.00% 35 389
1 0 0 100.00% 35 389
0 0 0 0.00% 35 389·HITS:缓存命中的次数;
·MISSES:缓存未命中的次数;
·DIRTIES:新增到缓存中的脏页数;
·BUFFERS_MB:Buffers 的大小,单位:MB;
·CACHED_MB:Cache 的大小,单位:MB;
cachetop 查看进程的缓存读写命中情况:
17:53:23 Buffers MB: 27 / Cached MB: 393 / Sort: HITS / Order: descending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
491 root jbd2/vda1-8 4 2 2 33.3% 33.3%
132708 root cachetop 2 0 0 100.0% 0.0%READ_HIT 和 WRITE_HIT 分别表示读和写的缓存命中率。
指定文件的缓存大小
可以使用 pcstat 查看文件在内存中的缓存大小以及缓存比例。pcstat 是 Go 语言开发的,具体安装步骤可自行查询。
内存泄漏
栈内存是由系统自动分配和管理,一旦程序运行超出了这个局部变量的作用域,栈内存就会被系统自动回收,所以不会产生内存泄漏。堆内存是由应用程序来分配和管理,除非程序退出,这些堆内存并不会被系统自动释放,而是需要程序明确调用库函数来释放,所以可能会产生内存泄漏。
除了栈内存和堆内存,其他内存段也会导致内存泄漏:
·只读段,包括程序的代码和常量,由于是只读,不会再去分配新的内存,就不会产生内存泄漏;
·数据段,包括全局变量和静态变量,这些变量在定义时已经确定了大小,也就不会产生内存泄漏;
·内存映射段,包括动态链接库和共享内存,其中共享内存由程序动态分配和管理,如果程序忘了回收,就会出现内存泄漏问题。
定位内存泄漏
通过 vmstat 命令,可以查看内存变化情况:
# 每3秒输出一组数据
$ vmstat 3
procs --memory-- -swap- --io-- -system-- --cpu--
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 132448 95884 82524 355236 0 0 1 3 24 4 1 0 99 0 0重点关注 free、buff、cache 列的数据变化。如果 free 一直减少,而 buff 和 cache 基本不变,那就说明系统中使用的内存一直在升高,但这并不能说明有内存泄漏,那么怎么确定是不是内存泄漏呢?
专门检测内存泄漏的工具—— memleak。memleak 可以跟踪系统或指定进程的内存分配、释放请求,然后定期输出一个未释放内存和响应调用栈的汇总情况。使用这个命令需要安装 bcc 软件包。执行如下命令:
/usr/share/bcc/tools/memleak -a -p PIDSwap
Swap 会把一些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
Swap原理
Swap 就是把一块磁盘空间或者一个本地文件,当成内存来使用,它包括换出和换入两个过程。现在内存大多了,但也还是有不够用的时候,一个典型的场景是:当内存不足时,有些应用程序不想被 OOM 杀死,而是希望能缓一段时间,等待人工介入或者等系统自动释放其他进程的内存,再分配给它。
Swap 是为了回收内存,Linux 一般会在内存紧张的时候回收内存,那该怎么衡量内存是不是紧张呢?
一个最容易想到的场景就是,有新的大块内存分配请求,但是剩余内存不足,这个时候系统就需要回收一部分内存(比如缓存),进而尽可能地满足新内存请求。这个过程通常被称为直接内存回收。
此外,还有一个专门的内核线程用来定期回收内存,也就是kswapd0。为了衡量内存的使用情况,kswapd0 又定义了三个内存阈值,分别是:页最小阈值(pages_min)、页低阈值(pages_low)和页高阈值(pages_high)。它们的关系如下图:(pages_free 是剩余内存)
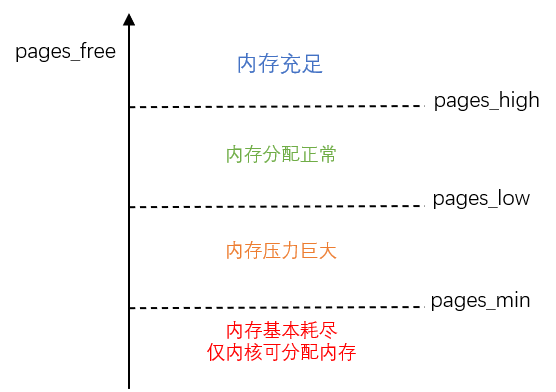
一旦剩余内存小于页低阈值,就会触发内存回收。页最小阈值可以通过设置内核选项来修改:/proc/sys/vm/min_free_kbytes,另两个阈值是根据页最小阈值计算生成的:
pages_low = pages_min * 5 / 4
pages_high = pages_min * 3 / 2可通过下面的命令查看这三个阈值:
$ cat /proc/zoneinfo
...
Node 0, zone DMA
pages free 1176
min 190
low 237
high 284
...
nr_free_pages 1176
nr_zone_inactive_anon 1422
nr_zone_active_anon 57
nr_zone_inactive_file 859
nr_zone_active_file 184其中 Node 0,可以了解处理器的 NUMA 架构,多个处理器被划分到不同的 Node 上,同一个 Node,又可以进一步分为内存域(Zone),比如直接内存访问区(DMA)、普通内存区(NORMAL)、伪内存区(MOVABLE)等。
swappiness
内存回收有两种机制,分别是回收文件页和回收匿名页。Linux 提供了 /proc/sys/vm/swappiness 配置来调整使用 Swap 的积极程度。swappiness 的范围是 0 ~ 100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页。
I/O 性能
文件系统
索引节点和目录项
Linux 文件系统为每个文件都分配了两个数据结构:索引节点(index node)和目录项(directory entry),它们主要用来记录文件的元信息和目录结构。
索引节点是每个文件的唯一标识,而目录项维护的正是文件系统的树状结构,目录项和索引节点的关系是多对一。例如硬连接为文件创建别名,不同的别名本质上还是链接同一个文件,它们的索引节点是相同的。
虚拟文件系统
为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,引入了虚拟文件系统 VFS(Virtual File System)。这样用户进程和内核中的其他子系统,只需要和 VFS 提供的统一接口进行交互即可,而不需要再关注底层各种文件系统的实现细节。Linux 文件系统的关系如下图:
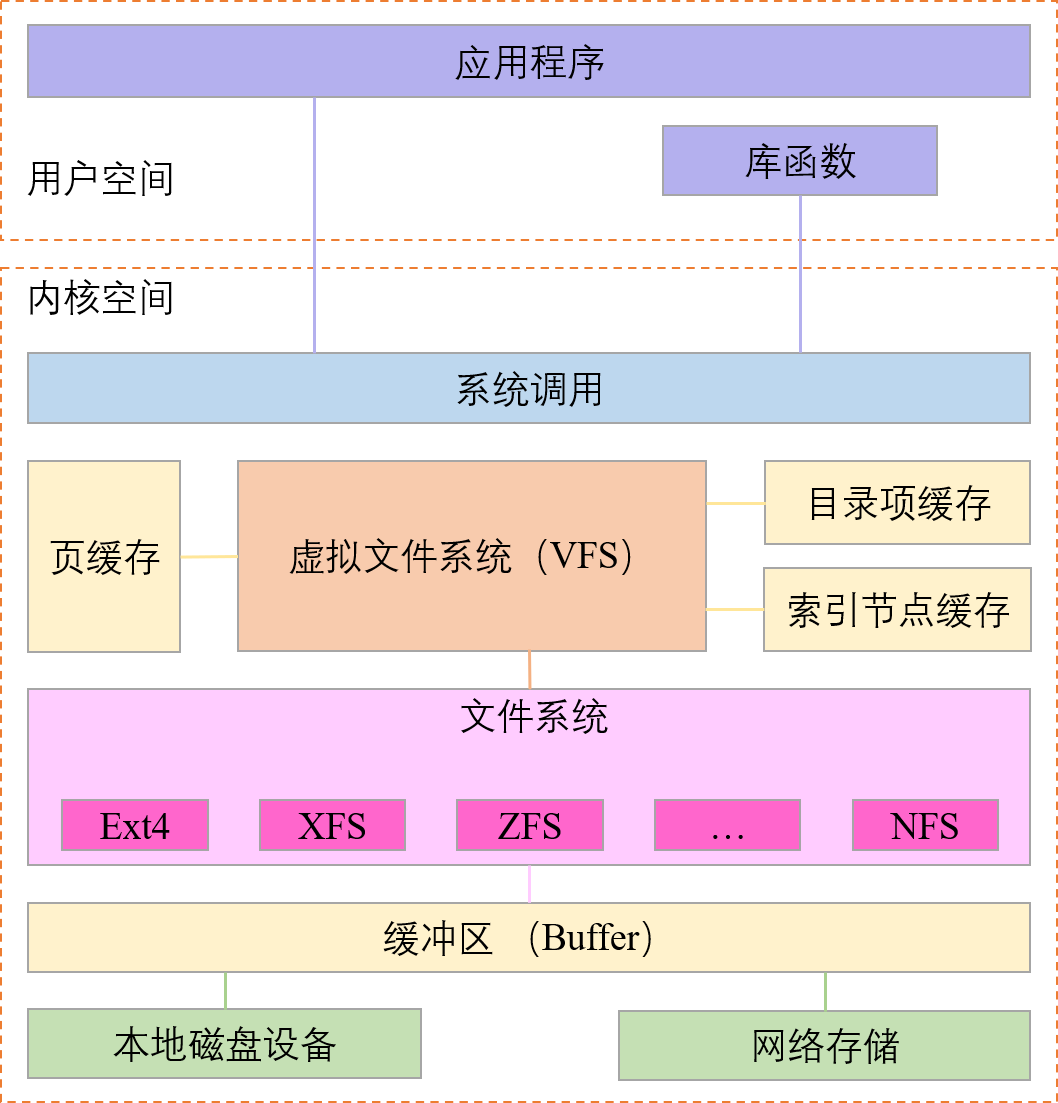
文件系统 I/O
文件系统 I/O 的分类多种多样,最常见的有:缓冲与非缓冲 I/O、直接与非直接 I/O、阻塞与非阻塞 I/O、同步与异步 I/O 等。
根据是否利用标准库函数,可以把文件 I/O 分为缓冲 I/O 与非缓冲 I/O。这里所说的“缓冲”,是指标准库内部实现的缓存。系统调用后,还会通过页缓存来减少磁盘的 I/O 操作。
根据是否利用操作系统的页缓存,可以把文件 I/O 分为直接 I/O 与非直接 I/O。要想实现直接 I/O,需要再系统调用中,指定 O_DIRECT 标志,默认是非直接 I/O。
根据应用程序是否阻塞自身运行,可以把文件 I/O 分为阻塞 I/O 与非阻塞 I/O。比如访问网络套接字时,设置 O_NONBLOCK 标志,就表示用非阻塞方式访问,默认是阻塞访问。
根据是否等待响应结果,可以把文件 I/O 分为同步 I/O 与异步 I/O。
通用块层
通用块层,其实是处在文件系统和磁盘驱动中间的一个块设备抽象层,Linux 通过这个通用块层来管理各种不同的块设备,它主要有两个功能:
·跟虚拟文件系统的功能类似。向上,为文件系统和应用程序提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
·给文件系统和应用程序发来的 I/O 请求排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
对 I/O 请求排序的过程就是 I/O 调度,Linux 内核支持四种 I/O 调度算法,分别是 NONE、NOOP、CFQ 和 DeadLine。
磁盘性能指标
衡量磁盘性能的基本指标常用的有:使用率、饱和度、IOPS、吞吐量和响应时间等:
·使用率:磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
·饱和度:磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈,当饱和度为 100% 时,磁盘无法接收新的 I/O 请求。
·IOPS:每秒的 I/O 请求数。
·吞吐量:每秒的 I/O 请求大小。
·响应时间:I/O 请求从发出到收到响应的间隔时间。
评估磁盘整体性能时,不能孤立去看某一指标,要结合读写比例、I/O 类型(随机还是连续)以及 I/O 的大小来综合分析。比如:在数据库和大量小文件等这类随机读写比较多的场景中,IOPS 更能反映系统的整体性能;而在多媒体文件等顺序读写较多的场景中,吞吐量才更能反应系统的整体性能。
常用的磁盘性能测试工具是 fio,需要测试不同 I/O 大小(一般是 512B 至 1MB 中间的若干值)分别在随机读、随机写、顺序读、顺序写等各种场景下的性能情况。
I/O基准测试
fio 是最常用的文件系统和磁盘 I/O 性能基准测试工具。常见测试场景如下:
# 随机读
fio -name=randread -direct=1 -iodepth=64 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 随机写
fio -name=randwrite -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序读
fio -name=read -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序写
fio -name=write -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb以上,重要参数如下:
·direct:表示是否跳过系统缓存,设置成 1 就表示跳过系统缓存。
·ioengine:表示 I/O 引擎,支持同步(sync)、异步(libaio)、内存映射(mmap)、网络(net)等各种 I/O 引擎。
·iodepth:表示使用异步 I/O 时,发出的 I/O 请求上限。
·rw:表示 I/O 模式。
·bs:表示 I/O 的大小,默认值为 4K。
·filename:表示文件路径。
fio 的测试报告中,需要重点关注 slat、clat、lat、bw、iops 这几行结果,它们的含义如下:
·slat、clat、lat 都是指 I/O 延迟,lat = slat + clat,对于同步 I/O,clat 一般为 0;对于异步 I/O,lat 近似等于 slat + clat 之和。
·bw:表示吞吐量。
·iops:表示每秒 I/O 的次数。
但是,通常情况下,磁盘的 I/O 都是读写并行的,且每次 I/O 大小也不一样,所以上述的测试场景并不能精确模拟应用程序的 I/O 模式。为了能够得到应用程序 I/O 模式的基准测试报告,可以执行下面命令:
# 跟踪磁盘I/O,必须是应用程序正在操作的磁盘
$ blktrace /dev/sda
# 查看blktrace记录结果
$ ls
sda.blktrace.0 sda.blktrace.1
# 将结果转成二进制文件
$ blkparse sda -d sda.bin
# 使用 fio 重放日志
$ fio --name=replay --filename=/dev/sda --direct=1 --read_iolog=sda.bin磁盘I/O指标
iostat 是最常用的查看磁盘 I/O 的性能。iostat 输出如下:
$ iostat -d -x 1
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
vda 0.10 2.30 0.01 11.45 3.93 23.77 0.44 4.56 0.43 49.57 0.79 10.46 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.04·r/s 和 w/s:每秒发送给磁盘的读/写请求,是合并后请求数
·rkB/s 和 wkB/s:每秒从磁盘读取/写入的数据量,单位为 KB。
·rrqm/s 和 wrqm/s:每秒合并的读/写请求,表示合并读/写请求的百分比
·r_await 和 w_await:读/写请求处理完成时间,包括队列中的等待时间和设备实际处理的时间,单位是毫秒。
·rareq-sz 和 wareq-sz:平均读/写请求大小,单位为kB
·aqu-sz:平均请求队列长度。
·f/s:每秒钟完成的文件系统操作次数。反映了系统对文件系统的访问频率,数值越高,通常表示文件系统越繁忙。
·f_await:表示文件系统操作的平均等待时间,单位是毫秒。这个时间包括了请求在队列中等待的时间以及实际处理请求的时间。较高的值可能表明文件系统存在性能瓶颈。
·%util:磁盘处于活动状态的时间百分比,即使用率。由于可能存在并行的 I/O,100% 并不一定表明磁盘 I/O 饱和。
·d/s 和 dkB/s 等指标是抛弃请求的数据,用来衡量存储设备的管理效率,较高的抛弃请求指标可能表示系统频繁进行数据删除或清理操作。
这些指标中:
·r/s + w/s,就是 IOPS。
·rkB/s + wkB/s,就是吞吐量。
·r_await + w_await,就是响应时间。
在分析磁盘性能时,还需要结合请求的大小(rareq-sz 和 wareq-sz)一起分析。
进程I/O指标
查看进程的 I/O 数据可使用 pidstat 和 iotop 工具。
系统I/O瓶颈分析
系统 I/O 问题排查的过程如下,可参考使用。
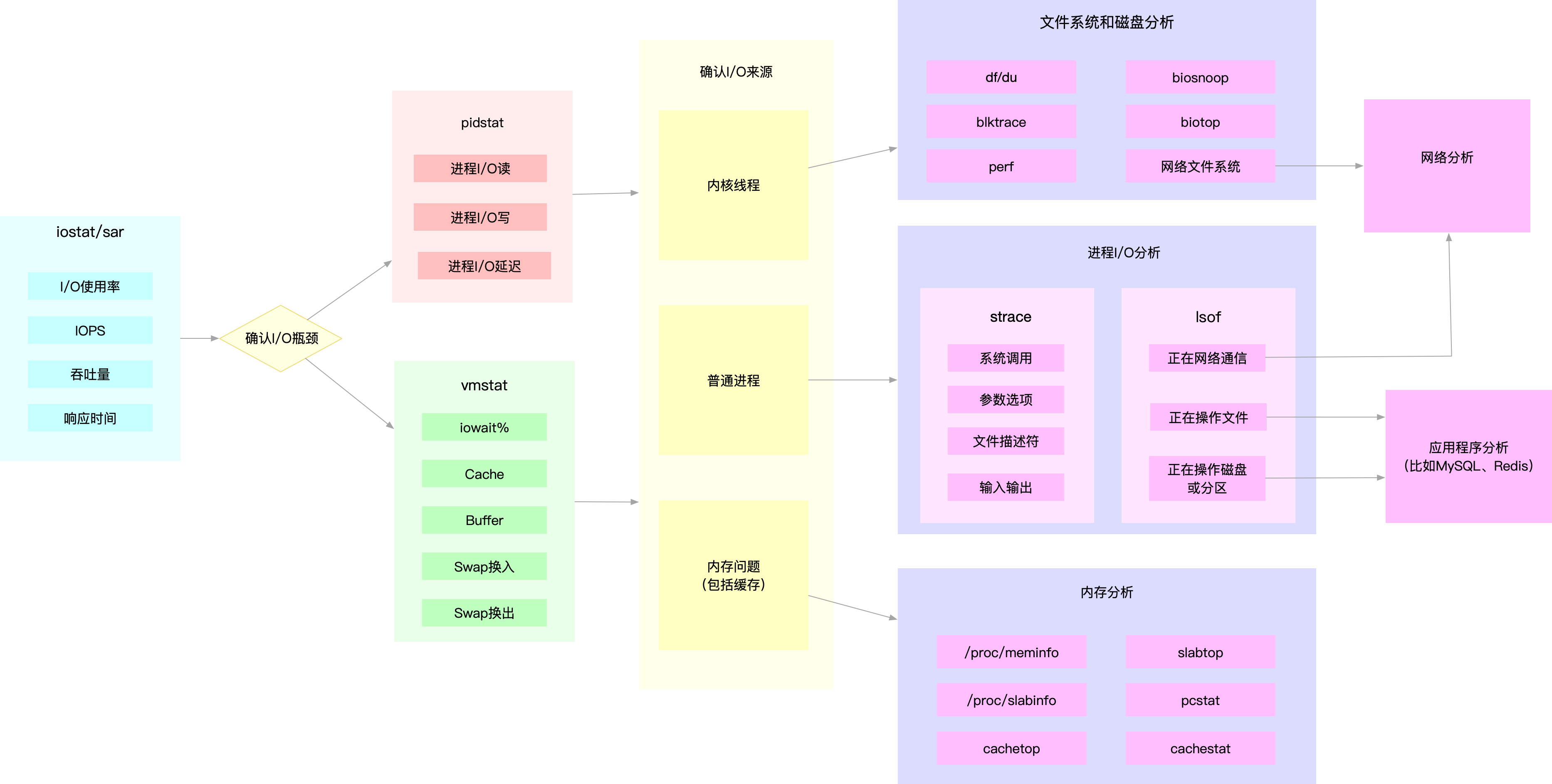
I/O 指标查询的工具或命令汇总如下:
·iostat:磁盘 I/O 使用率、IOPS、吞吐量、响应时间、I/O 平均大小以及等待队列长度
·pidstat:进程 I/O 大小、I/O 延迟
·sar:磁盘 I/O 使用率、IOPS、吞吐量、响应时间
·dstat:磁盘 I/O 使用率、IOPS、吞吐量
·iotop:按 I/O 大小对进程排序
·slabtop:目录项、索引节点、文件系统缓存
·/proc/slabinfo:目录项、索引节点、文件系统缓存
·/proc/meminfo:页缓存、可回收 slab 缓存
·/proc/diskstats:磁盘的 IOPS、吞吐量、延迟
·/proc/pid/io:进程 IOPS、I/O 大小、I/O 延迟
·vmstat:缓存和缓冲区用量汇总
·blktrace:跟踪块设备 I/O 事件
·biosnoop:跟踪进程的块设备 I/O 大小
·biotop:跟踪进程块 I/O 并按 I/O 大小排序
·strace:跟踪进程的 I/O 系统调用
·perf:跟踪内核中的 I/O 事件
·tune2fs:显示和设置文件系统参数
·hdparm:显示和设置磁盘参数
排查读写磁盘的问题
首先使用 top 命令,查看 CPU 使用率(iowait使用率),然后再看看内存和 Swap,特别注意剩余内存和缓存的大小。
其次使用 iostat 命令查看磁盘的 I/O 使用情况,需要关注读写磁盘的请求数、大小、响应时间,以及请求队列长度和使用率。
最后可以使用 pidstat -d 1 命令查看每个进程的 I/O 数据,需要关注每秒读写大小和 iodelay。
以上基本上可以确定是不是真的存在磁盘 I/O 问题。对于问题排查,还需要查看进程具体在干什么?
可通过 strace -f -p PID 命令查看进程的系统调用,其中 read() 或 write() 可以查看进程操作文件描述符的数据;stat() 可以查看读写文件路径。可通过 lsof -p PID 命令查看进程打开的文件列表,重点关注 FD(文件描述符号,描述符为数字,数字后的字母表示读(r)、写(w)、读写(u)),可以进一步确认进程读写文件的路径。
如果查不到任何读写磁盘的数据,或者读写磁盘的数据很小不足以产生性能问题,那么可以使用 /usr/share/bcc/tools/filetop -C 命令跟踪内核中的文件读写情况;然后通过线程ID 查看具体是哪个进程 ps -efT | grep TID;使用命令 /usr/share/bcc/tools/opensnoop 跟踪内核中 open 系统调用,查看具体的文件路径。
排查慢SQL问题
整体思路和上一节一样,依次是:
1、执行 top、iostat -d -x 1 和 pidstat -d 1 命令,查看 CPU 使用率,iowait 使用率、内存、缓存、磁盘I/O 等数据;
2、跟踪系统调用,使用 strace -f -p PID 和 lsof -p PID 命令,查看具体在读写哪个文件;
3、对于 MySQL 数据库,执行 show full processlist 命令查询正在执行的 SQL 语句,可多执行几次对比;其他类型的数据库也都有对应的查询语句,Oracle 数据库甚至可以直接导出 AWR 报告;
现在的数据库基本都提供了查询慢 SQL 的语句或方法,一般情况下直接执行就可以了,不需要执行上面的第一步和第二步,这里只是提供了通用的排查思路,对于极少数复杂难定位的问题,也可以借鉴这个思路。
磁盘 I/O 性能优化思路
应用程序优化
应用程序处于整个 I/O 栈的最上端,是 I/O 数据的最终来源,可以有下面几种方式来优化应用程序的 I/O 性能:
1、可以用追加写代替随机写,减少寻址开销,加快 I/O 写的速度。
2、可以借助缓存 I/O,充分利用系统缓存,降低实际 I/O 的次数。
3、可以在应用程序内部构件自己的缓存,或者使用 redis 这类的外部缓存。
4、在需要频繁读写同一块磁盘空间时,可以用 mmap 代替 read/write,减少内存拷贝次数。
5、在需要同步写的场景中,尽量将写请求合并,而不是让每个请求都写磁盘,即可以用 fsync() 取代 O_SYNC。
6、在多个应用程序共享磁盘时,为了保证 I/O 不被某个应用完全占用,可以使用 cgroups 的 I/O 子系统,来限制进程的 IOPS 以及吞吐量。
7、在使用 CFQ 调度器时,可以用 ionice 来调整进程的 I/O 调用优先级,特别是提高核心应用的 I/O 优先级。ionice 支持三个优先级类:Idle、Best-effort、Realtime。
文件系统优化
应用程序访问普通文件时,实际是由文件系统间接负责文件在磁盘中的读写。所以也有如下几种优化方式:
1、根据实际负载场景的不同,选择最合适的文件系统,比如:ext4、xfs 等。
2、优化文件系统的配置选项,包括文件系统的特性(如 ext_attr、dir_index)、日志模式(如 journal、ordered、writeback)、挂载项(如 noatime)等待。
3、优化文件系统的缓存,如:可以优化 pdflush 脏页的刷新频率以及脏页的限额;可以优化内核回收目录项缓存和索引节点缓存的倾向,vfs_cache_pressure 的数值越大表示越容易回收。
4、在不需要持久化时,可以用内存文件系统 tmpfs,以获得更好的 I/O 性能。
磁盘优化
数据持久化存储最终还是需要落到具体的物理磁盘中,磁盘也是整个 I/O 栈的最底层,可以由以下几种优化方法:
1、使用 RAID 把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列。
2、根据磁盘和应用程序 I/O 模式的特征,选择最合适的 I/O 调度算法。
3、对系统不同的数据,进行磁盘级别的隔离,可以为 I/O 压力比较重的应用配置单独的磁盘。
4、在顺序读比较多的场景中,可以增大磁盘的预读数据。如调整 /dev/sda 的预读大小:调整内核选项:/sys/block/sda/queue/read_ahead_kb,默认大小是 128KB,单位为 KB。
5、优化内核块设备 I/O 的选项。如调整磁盘队列的长度 /sys/block/sda/queue/nr_requests,适当增大队列长度可以提升磁盘的吞吐量(会导致 I/O 延迟增大)。
6、磁盘本身出现硬件错误也会导致 I/O 性能急剧下降。如查看 dmesg 是否有硬件 I/O 故障的日志。
网络性能
网络性能指标
网络常用的性能指标有:带宽、吞吐量、延时、PPS、并发连接数、丢包率、重传率。
网络基准测试
Linux 网络基于 TCP/IP 协议栈,在测试之前,必须要知道要评估的网络性能属于协议栈的哪一层?底层协议是其上层协议的基础,自然底层协议的性能也就决定了上层网络的性能。
转发性能
网络接口层和网络层,主要负责网络包的封装、寻址、路由以及发送和接收。在这两个网络协议层中,每秒处理的网络包数 PPS 就是最重要的性能指标,特别时 64B 小包的处理能力。
Linux 内核自带高性能网络测试工具 pktgen,pktgen作为一个内核线程来运行的,需要先加载 pktgen 内核模块,再通过 /proc 文件系统来交互:
$ modprobe pktgen
$ ps -ef | grep pktgen |grep -v grep
$ ls /proc/net/pktgen如果 modprobe 命令执行失败,说明内核没有配置 CONFIG_NET_PKTGEN 选项。
这个转发性能测试起来很麻烦,具体步骤可以查阅资料。
TCP/UDP性能
iperf 和 netperf 都是最常用的网络性能测试工具,测试 TCP 和 UDP 的吞吐量。它们都以客户端和服务器通信的方式,测试一段时间内的平均吞吐量。iperf 测试命令如下:
在目标机器上启动 iperf 服务端:
$ iperf3 -s -i 1 -p 11111在另一台机器上运行 iperf 客户端:
# -c 和 -p 分别是服务端的 ip 和 端口
# -b 表示目标带宽
# -t 表示测试时间
# -P 表示并发数
$ iperf3 -c 192.168.1.20 -p 11111 -b 1G -t 15 -P 2HTTP性能
测试 HTTP 的性能主要是:每秒请求数、请求延迟、吞吐量以及请求延迟的分布情况等。ab 和 webbench 都是常用的 HTTP 压力测试工具。
应用负载性能
测试了 TCP、HTTP 等的性能数据后,并不能表示应用程序的实际性能,为了得到应用程序的实际性能,就需要性能工具本身可以模拟用户的请求负载,可以使用 wrk、TCPCopy、Jmeter 和 LoadRunner 等工具。
分析网络流量
tcpdump 和 Wireshark 是最常用的网络抓包和分析工具,在实际分析网络性能时,先用 tcpdump 抓包,再用 Wireshark 分析。
tcpdump 抓包命令如下,更详细的命令参数可查阅资料。
$ tcpdump -nn udp port 53 or host 192.168.1.20tcpdump 的输出格式如下:
时间戳 协议 源地址.源端口 > 目标地址.目标端口 网络包详细信息如需把网络包保存到文件中,并导出在 Wireshark 中分析,则可执行下面命令:
$ tcpdump -nn udp port 53 or host 192.168.1.20 -w test.pcap网络性能优化
套接字
Linux 套接字内核参数调整:
| 内核选项 | 含义 | 参考值设置 |
|---|---|---|
| net.core.optmem_max | 每个套接字的缓冲区大小 | 81920 |
| net.core.rmem_max | 每个套接字接收缓冲区大小 | 513920 |
| net.core.wmem_max | 每个套接字发送缓冲区大小 | 513920 |
| net.ipv4.tcp_rmem | TCP 接收缓冲区范围 | 4096 87380 16777216 |
| net.ipv4.tcp_wmem | TCP 发送缓冲区范围 | 4096 65536 16777216 |
| net.ipv4.udp_mem | UDP 缓冲区范围 | 188562 251418 377124 |
传输层
TCP 提供了面向连接的可靠传输服务,可以进行下面的优化:
第一类,在请求数比较大的场景下,可能会看到大量处于 TIME_WAIT 状态的连接,它们会占用大量的内存和端口资源,可采取如下措施:
·增大处于 TIME_WAIT 状态的连接数量 net.ipv4.tcp_max_tw_buckets,并增大连接跟踪表的大小 net.netfilter.nf_conntrack_max。
·减小 net.ipv4.tcp_fin_timeout 和 net.netfilter.nf_conntrack_tcp_timeout_time_wait,让系统尽快释放它们所占用的资源。
·开启端口复用 net.ipv4.tcp_tw_reuse。
·增大本地端口的范围 net.ipv4.ip_local_port_range,就可以支持更多连接。
·增加最大文件描述符的数量。
第二类,为了缓解 SYN_FLOOD 等,优化与 SYN 状态相关的内核选项:
·增大 TCP 半连接的最大数量 net.ipv4.tcp_max_syn_backlog,或者开启 TCP SYN Cookies net.ipv4.tcp_syncookies 来绕开半连接数量限制。
·减少 SYN_RECV 状态的连接重传 SYN+ACK 包的次数 net.ipv4.tcp_synack_retries。
第三类,在长连接场景中,需要优化与 keepalive 相关的内核选项:
·缩短最后一次数据包到 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_time。
·缩短发送 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_intvl。
·减少 Keepalive 探测失败后,一直到通知应用程序前的重试次数 net.ipv4.tcp_keepalive_probes。
网络层
网络层优化,主要就是对路由、IP 分片以及 ICMP 等进行调优。
第一种,从路由和转发的角度,调整下面的内核选项:
·在需要转发的服务器中,比如用作 NAT 网关的服务器或者使用 Docker 容器时,开启 IP 转发,即设置 net.ipv4.ip_forward = 1。
·调整数据包的生存周期 TTL,设置 net.ipv4.ip_default_ttl = 64。注意,增大该值会降低系统性能。
·开启数据包的反向地址校验,设置 net.ipv4.conf.eth0.rp_filter = 1。这样可以防止 IP 欺骗,并减少伪造 IP 带来的 DDoS 问题。
第二种,从分片角度,主要调整 MTU 的大小:
通常,MTU 的大小应该根据以太网的标准来设置,默认 MTU = 1500。如果网络设备支持巨帧,MTU 可调大为 9000,以提高网络吞吐量。
第三种,从 ICMP 的角度,可通过设置内核选项,来限制 ICMP 的行为:
·可以禁止 ICMP 协议,设置 net.ipv4.icmp_echo_ignore_all = 1。这样外部主机就无法通过 ICMP 来探测主机。
·可以禁止广播 ICMP,设置 net.ipv4.icmp_echo_ignore_broadcasts = 1。
链路层
链路层负责网络包在物理网络中的传输,可以从 MAC 寻址、错误帧测、网卡传输到网络中、硬中断和软中断等方面进行优化,这部分在实际中一般不会去调优,这里就不介绍了。
服务器时不时丢包分析
要理解网络丢包的原理,就需要知道网络包的收发流程,如下图。从图中可以看出,在网络协议栈的任何一个地方都有可能丢包:
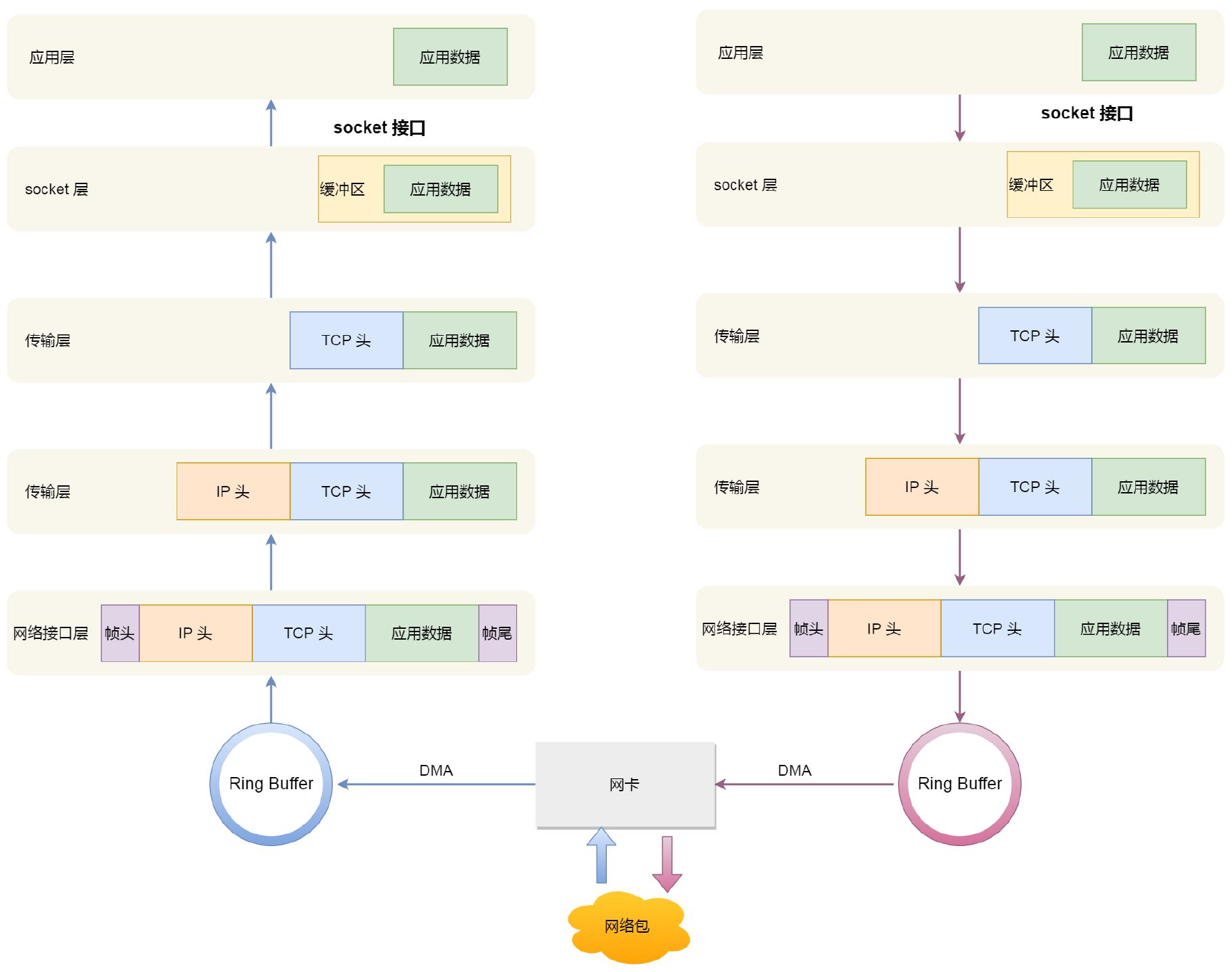
链路层丢包
当缓冲区溢出等原因导致网卡丢包时,Linux 会在网卡收发数据的统计信息中,记录下收发错误的次数。可通过 ethtool 或 netstat 来查看网卡丢包数据:
$ netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 1500 31550736 0 2283782 0 7566922 0 0 0 BMRU
lo 65536 4126961 0 0 0 4126961 0 0 0 LRURX-OK、RX-ERR、RX-DRP、RX-OVR 分别表示接收时的总包数、总错误数、进入 Ring Buffer 后因其他原因导致的丢包数、Ring Buffer 溢出导致的丢包数。
TX-OK、TX-ERR、TX-DRP、TX-OVR 表示类似的含义,只不过是指发送时的各个指标。
网络层和传输层丢包
Linux 已经提供了各个协议的收发汇总情况,执行 netstat -s 命令即可。
·IP 协议接受丢包数:incoming packets discarded
·ICMP 协议失败数:ICMP messages failed
·TCP 主动连接数:active connection openings
·TCP 被动连接数:passive connection openings
·TCP 失败连接尝试数:failed connection attempts
·TCP 接收的连接重置数:connection resets received
·TCP 发送的连接重置数:resets sent
·TCP 已接收报文数:segments received
·TCP 已发送报文数:segments sent out
·TCP 重传报文数:segments retransmitted
·TCP 错误报文数:bad segments received
·TcpExt 半连接重置数:resets received for embryonic SYN_RECV sockets
·TcpExt 超时数:TCPTimeouts
·TcpExt SYN 重传数:TCPSynRetrans
通过上面丢包数据的查询,再结合抓包工具 tcpdump 具体分析详细的问题。
动态追踪
动态追踪技术,通过探针机制,来采集内核或者应用程序的运行信息,从而可以不用修改内核和应用程序的代码,就获得丰富的信息,帮助分析 、定位想要排查的问题。
Linux 提供了一系列的动态跟踪机制,如 ftrace、perf、eBPF、SystemTap、BCC、sysdig。
perf
除了 perf record/top/report 外,perf 还有很多其他功能,可通过 perf list 可以查询所有支持的事件。以内核函数 do_sys_open 为例:
$ perf probe --add do_sys_open对 do_sys_open 进行采样:
$ perf record -e probe:do_sys_open -aR sleep 5查看采样结果:perf script
perf 194444 [001] 4881626.304465: probe:do_sys_open: (ffffffff9cb2dc50)
tuned 1044 [000] 4881626.307777: probe:do_sys_open: (ffffffff9cb2dc50)
sleep 194445 [001] 4881626.307800: probe:do_sys_open: (ffffffff9cb2dc50)
sleep 194445 [001] 4881626.307824: probe:do_sys_open: (ffffffff9cb2dc50)
tuned 1044 [000] 4881626.308017: probe:do_sys_open: (ffffffff9cb2dc50)不过,对于 open 系统调用来说,只知道它被调用了并不够,还要知道进程到底在打开哪些文件,最简单的方法是从调试符号表中查询所有参数:
$ perf probe -V do_sys_open
Available variables at do_sys_open
@<do_sys_open+0>
char* filename
int dfd
int flags
struct open_flags op
umode_t mode文件路径就是字符指针参数 filename。
如果命令执行失败,说明调试符号表还没有安装,那就需要先安装再使用:
# Ubuntu
$ apt-get install linux-image-`uname -r`-dbgsym
# CentOS
$ yum --enablerepo=base-debuginfo install -y kernel-debuginfo-$(uname -r)找出参数名称和类型后,就可以把参数加到探针中了:
# 先删除旧的探针
$ perf probe --del probe:do_sys_open
# 添加带参数的探针
$ perf probe --add 'do_sys_open filename:string'
# 重新采样记录
$ perf record -e probe:do_sys_open -aR sleep 5
# 查看结果
$ perf script
perf 195926 [001] 4885737.311502: probe:do_sys_open: (ffffffff9cb2dc50) filename_string="/proc/195927/status"
tuned 1044 [001] 4885737.321244: probe:do_sys_open: (ffffffff9cb2dc50) filename_string="/proc/195927/cmdline"
sleep 195927 [000] 4885737.321790: probe:do_sys_open: (ffffffff9cb2dc50) filename_string="/etc/ld.so.cache"
sleep 195927 [000] 4885737.321855: probe:do_sys_open: (ffffffff9cb2dc50) filename_string="/lib64/libc.so.6"
# 使用完成后一定要删除探针
$ perf probe --del probe:do_sys_open其实,使用 strace 跟踪进程的系统调用时,也可以看到和上面相似的结果,以 ls 为例:
$ strace ls
access("/etc/selinux/config", F_OK) = 0
openat(AT_FDCWD, "/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/usr/share/locale/locale.alias", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=2997, ...}) = 0既然 strace 能得到相似的结果,操作又简单,那为什么还要用 perf 呢?实际上,strace 会影响进程的性能。strace 基于系统调用 ptrace 实现:
·由于 ptrace 是系统调用,就需要在内核态和用户态切换。当事件数量比较多时,繁忙的切换必然会影响原有服务的性能;
·ptrace 需要借助 SIGSTOP 信号挂起目标进程。这种信号控制进程挂起,会影响目标进程的行为。
perf 也有和 strace 类似的功能,perf trace 是基于内核事件:
$ perf trace ls
0.269 ( 0.007 ms): ls/196571 fstat(fd: 3, statbuf: 0x7fff5adf3840) = 0
0.281 ( 0.014 ms): ls/196571 mmap(len: 23343, prot: READ, flags: PRIVATE, fd: 3) = 0x7f1fd260c000
0.301 ( 0.006 ms): ls/196571 close(fd: 3) = 0
0.327 ( 0.018 ms): ls/196571 openat(dfd: CWD, filename: 0xd2614df0, flags: RDONLY|CLOEXEC) = 3查询所有支持的函数和函数参数:
# 查询所有的函数
$ perf probe -x /bin/bash --funcs
# 查询函数的参数
$ perf probe -x /bin/bash -V readline如果执行上面的命令报错:没有调试信息。则可执行下面命令安装它:
# Ubuntu
apt-get install -y bash-dbgsym
# CentOS
debuginfo-install bashftrace
ftrace 通过 debugfs(或 tracefs)为用户空间提供接口。首先需要切换到 debugfs 挂载点:
$ cd /sys/kernel/debug/tracing
$ ls如果这个目录不存在,则说明系统还没有挂载 debugfs,执行下面命令挂载它:
$ mount -t debugfs nodev /sys/kernel/debugftrace 提供了多个跟踪器,用于跟踪不同类型的信息,比如函数调用、中断关闭、进程调度等,执行下面命令查询所有支持的跟踪器:
$ cat available_tracers
hwlat blk function_graph wakeup_dl wakeup_rt wakeup function nop其中,function 表示跟踪函数执行,function_graph 表示跟踪函数的调用关系。
执行下面命令查询支持的函数和事件:
$ cat available_filter_functions
$ cat available_eventsftrace的使用方法
ls 命令会通过 open 系统调用打开目录文件,而 open 在内核中对应的函数名为 do_sys_open。以 ls 命令为例,了解 ftrace 的使用方法。
第一步,把要跟踪的函数设置为 do_sys_open:
$ echo do_sys_open > /sys/kernel/debug/tracing/set_graph_function第二步,配置跟踪选项,开启函数调用跟踪,并跟踪调用进程:
$ echo function_graph > /sys/kernel/debug/tracing/current_tracer
$ echo funcgraph-proc > /sys/kernel/debug/tracing/trace_options第三步,开启跟踪:
$ echo 1 > /sys/kernel/debug/tracing/tracing_on第四步,执行 ls 命令后,再关闭跟踪:
$ ls
$ echo 0 > /sys/kernel/debug/tracing/tracing_on第五步,查看跟踪结果:
$ cat /sys/kernel/debug/tracing/trace以上需要 5 步,太麻烦了,可以使用 trace-cmd 工具,一个命令完成上述所有过程:
# 安装 trace-cmd
# Ubuntu
$ apt-get install trace-cmd
# CentOs
$ yum install trace-cmd
$ trace-cmd record -p function_graph -g do_sys_open -O funcgraph-proc ls
$ trace-cmd reporteBPF和BCC
ftrace 和 perf 的功能以及比较丰富了,不过它们有一个共同的缺陷就是不够灵活,没法像 DTrace 那样通过脚本自由扩展。具体用法这里就不介绍了。
SystemTap和sysdig
SystemTap 和 sysdig 也是常用的动态追踪工具,具体用法这里就不介绍了。
优化性能问题的一般方法
CPU优化
CPU 性能优化的核心在于排除所有不必要的工作、充分利用 CPU 缓存并减少进程调度对性能的影响。有如下最典型的三种优化方法:
·第一种,把进程绑定到一个或者多个 CPU 上,充分利用 CPU 缓存的本地性,减少进程间的相互影响。
·第二种,为中断处理程序开启多 CPU 负载均衡,以便在发生大量中断时,可以充分利用多 CPU 的优势分摊负载。
·第三种,使用 Cgroups 等方法,为进程设置资源限制,避免个别进程消耗过多的 CPU。同时,为核心应用程序设置更高的优先级,减少低优先级任务的影响。
内存优化
内存优化可以通过以下几种方法优化:
·第一种,除非有必要,Swap 应该禁止掉,这样就可以避免 Swap 的额外 I/O,带来内存访问变慢的问题。
·第二种,使用 Cgroups 等方法,为进程设置内存限制,这样就可以避免个别进程消耗过多内存,而影响了其他进程。对于核心应用,还应该降低 oom_score,避免被 OOM 杀死。
·第三种,使用大页、内存池等方法,减少内存的动态分配,从而减少缺页异常。
文件系统优化
磁盘和文件系统 I/O 的优化方法有这三种典型的方法:
·第一种,最简单的是通过 SSD 代替 HDD、或者使用 RAID 等方法,提升 I/O 性能。
·第二种,针对磁盘和应用程序 I/O 模式的特征,选择最适合的 I/O 调度算法。比如:SSD 和虚拟机中的磁盘,通常用的是 noop 调度算法;对于数据库应用,更推荐使用 deadline 算法。
·第三种,优化文件系统和磁盘的缓存、缓冲区,比如优化脏页的刷新频率、脏页限额,以及内核回收目录项缓存和索引节点缓存的倾向等。
除此之外,使用不同磁盘隔离不同应用的数据、优化文件系统的配置选项、优化磁盘预读、增大磁盘队列长度等也是常用的优化思路。
网络优化
针对 Linux 每个协议层的工作原理进行优化,最典型的几种方法如下:
首先,从内核资源和网络协议的角度来说,可以对内核选项进行优化,如下:
·增大套接字缓冲区、连接跟踪表、最大半连接数、最大文件描述符数、本地端口范围等内核资源配额;
·减少 TIMEOUT 超时时间、SYN+ACK 重传数、Keepalive 探测时间等异常处理参数;
·开启端口复用、反向地址校验,并调整 MTU 大小等降低内核的负担。
其次,从网络接口的角度来说,可以考虑对网络接口的功能进行优化,比如:
·将原来 CPU 上执行的工作,卸载到网卡中执行,即开启网卡的 GRO、GSO、RSS、VXLAN 等卸载功能;
·开启网络接口的多队列功能,这样每个队列就可以用不同的中断号,调度到不同 CPU 上执行;
·增大网络接口的缓冲区大小以及队列长度等,提升网络传输的吞吐量。
最后,在极限性能的情况下,内核的网络协议栈可能是最主要的性能瓶颈,所以可以考虑绕过内核协议栈:
·可以使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请求。同时再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率。
·还可以使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理。
应用程序优化
系统性能优化的最佳位置还是在应用程序内部。在观察性能指标时,应该先查看应用程序的响应时间、吞吐量、错误率等指标,从这些角度出发,推荐以下几种优化方法:
·第一,从 CPU 使用的角度,简化代码、优化算法、异步处理以及编译器优化等都是降低 CPU 使用率的方法;
·第二,从数据访问的角度,使用缓存、写时复制、增大 I/O 尺寸等都是减少磁盘 I/O 的方法;
·第三,从内存管理的角度,使用大页、内存池等方法,可以预先分配内存,减少内存的动态分配,从而更好地内存访问性能;
·第四,从网络的角度,使用 I/O 多路复用、长连接代替短连接、DNS 缓存等方法,可以优化网络 I/O 并减少网络请求数,从而减少网络延时带来的性能问题;
·第五,从进程的工作模型来说,异步处理、多线程或多进程等,可以充分利用每一个 CPU 的处理能力。从而提高应用程序的吞吐能力。
总结
最后拿一张其他大佬的图结束: