本文适合在那些基础设施建设比较差的公司的小伙伴阅读,如果你所在的公司的各种监控比较完善,那么本文不适合你。如果你只是因为做性能测试缺少监控,那么这篇文章提供了端到端的性能测试解决方案。
介绍
为什么要这个服务器资源监控工具呢?
首先,有相当一部分公司的服务器资源监控是分钟级的,还有相当一部分小伙伴做性能测试时仍在用 JMeter 的监控插件监控服务器资源,还有一些小伙伴在使用一些很难用且操作复杂的工具监控服务器资源。对于性能测试,如果出现性能问题,以上监控方法会大大影响性能问题的排查。
其次,目前开源的主流服务器资源监控工具(方案)的定位是运维监控,页面做的很好看,监控的数据很多,但因为页面太好看了,导致眼花缭乱,监控的很多数据实际上并没什么用,可能有用的数据它又没有,且部署复杂,工具本身占用系统资源较多,例如 Grafana+Zabbix+Prometheus 这套服务器资源监控方案。还有一个工具(nmon)基本满足我的需求,但是操作极其复杂,看了教程后,对它一点兴趣都没有了。
最后,因为我也遇到过服务器资源监控的问题,为了保证性能测试时服务器资源监控的准确性,于是决定自己动手写了一个服务器资源监控工具。此工具几乎可以运行在任何可以运行 Python 的 Linux 系统上,已经测试过的系统发行版本有 Ubuntu、CentOS、中标麒麟、银河麒麟,支持 X86_64 和 ARM 架构。
从 2019 年 5 月开始,随着学习理解的不断深入,随着实际使用过程中收到的各种建议,该工具前前后后已经重构了 3 次,commit 了 230 多次;不断地增加功能、优化性能、提高稳定性、改善用户体验,最终形成了这个部署简单、操作简单、页面简洁、运行稳定的最终版。虽然这个监控工具的页面看起来有点 low,但还是很实用的,已经得到了实践的检验,可以长期稳定可靠地运行。
功能
1、监控整个服务器的 CPU 使用率、Load、io wait、内存大小、磁盘IO、网络带宽和 TCP 连接数
2、监控指定端口的 CPU 使用率、内存占用大小、磁盘读写速率和 TCP 连接数
3、针对 java 应用,可以监控 jvm 大小和垃圾回收情况;当 Full GC 频率过高时,可发送邮件提醒
4、当系统 CPU 使用率过高,或者剩余内存过低时,可发送邮件提醒;可设置自动清理缓存
5、可随时启动/停止监控指定端口
6、当端口重启后,可自动重新监控
7、支持运维监控,端口停止后,可发送邮件提醒
8、可按照指定时间段可视化监控结果
9、数据采样频率最高可达约 1次/s,可设置任意采样频率
10、可同时管理监控多台服务器
11、服务端停止后,不影响 Agent 继续监控
技术选型
Web框架:aiohttp
模板渲染:jinja2
可视化:echarts
数据库:InfluxDB
部署
1、克隆项目
git clone https://github.com/leeyoshinari/performance_monitor.gitserver 文件夹是服务端,只需部署一个即可;agent 文件夹是客户端,部署在需要监控的服务器上
2、部署 InfluxDB2 数据库,可直接按照 InfluxDB 官网的步骤安装。安装完成后,用浏览器打开 web 页面,设置 Organization 和 bucket,获取 Token,将 Organization、bucket 和 Token 配置在 config.conf 中
3、分别修改 server 和 agent 文件夹里的配置文件 config.ini
4、检查 sysstat 版本。分别使用 iostat -V 和 pidstat -V 命令,12.7.5 版本已经测试过了,如果不是这个版本,请点我下载
5、分别运行 server 和 agent 文件夹中的 server.py
nohup python3 server.py &打包
如果代码能够正常运行,那么最好把代码进行打包,打包完成后,可快速在其他环境上部署该监控服务,而不需要在每个服务器上安装 python 环境。
注意:由于 agent 需要在待监控的服务器上运行,在 CentOS 系统 X86 架构的服务器上打包完成的可执行文件,只能运行在 CentOS 系统 X86 架构的服务器上;其他系统和架构的服务器需要重新在对应系统和架构的服务器上打包。
打包 server
1、执行打包命令:
pyinstaller --onefile --name=server server.py --hidden-import draw_performance --hidden-import config --hidden-import logger --hidden-import Email --hidden-import process --hidden-import request2、编辑 server.spec 文件,修改 pathex 为当前项目目录,例如:pathex=['/home/performance_monitor/server']
3、执行打包命令:pyinstaller server.spec
4、复制 config.ini 到 dist 目录,命令:cp config.ini dist/
5、将模板文件 templates 和静态文件 static 拷贝到 dist 文件夹下
6、将 dist 整个文件夹拷贝到其他环境,启动 server
nohup ./server &打包 agent
1、执行打包命令:
pyinstaller --onefile --name=server server.py --hidden-import logger --hidden-import performance_monitor --hidden-import common --hidden-import config2、编辑 server.spec 文件,修改 pathex 为当前项目目录,例如:pathex=['/home/performance_monitor/agent']
3、执行打包命令:pyinstaller server.spec
4、复制 config.ini 到 dist 目录,命令:cp config.ini dist/
5、将 dist 整个文件夹拷贝到其他环境,启动 server
nohup ./server &Server(服务端)
Server 主要用于前端页面展示和从数据库读取数据并显示,可以统一查看所有已监控的服务器的相关数据。前端所有页面均已适配 1920×1080 和 1366×768 的分辨率。
Server 启动过程
启动Server(服务端)后,会进行以下动作:
1、获取当前服务器 IP
2、启动服务,监听端口
3、修改数据库数据保留策略
4、初始化全局变量,等待 Agent 的注册
5、每隔 12s 检查 Agent 状态,将异常的 Agent 及时踢下线
首页
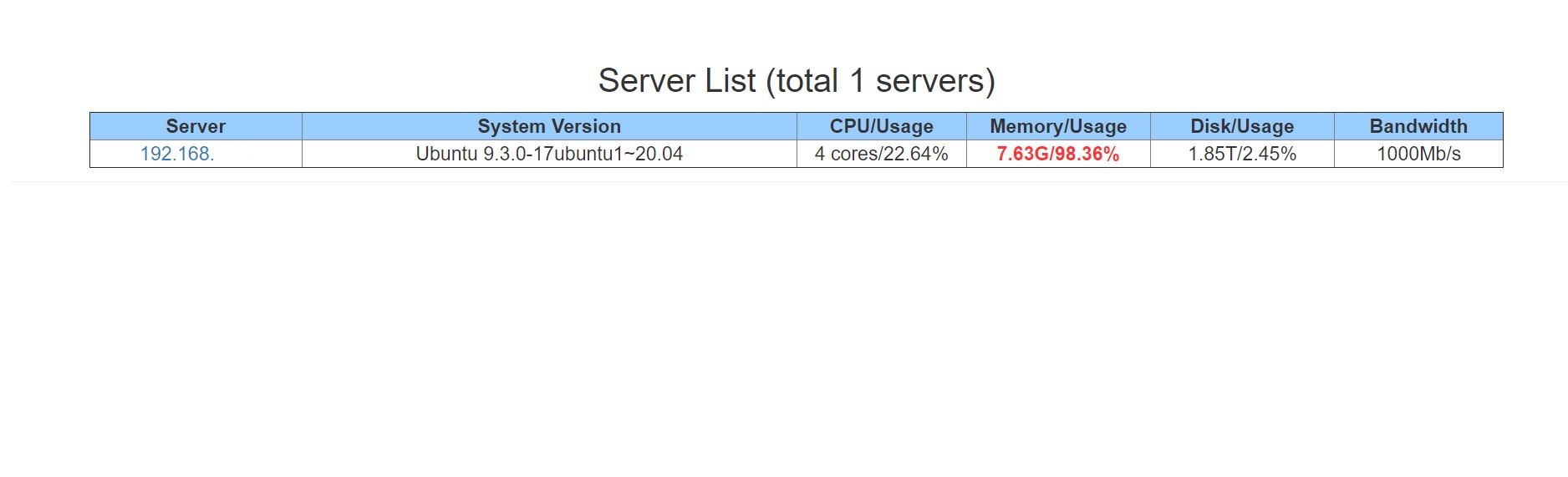
首页展示了当前已经监控的服务器的当前状态和基本信息,分别是当前服务器的 IP、系统版本、CPU核数/当前CPU使用率、物理内存/当前内存使用率、磁盘总大小/当前磁盘总使用率、网卡支持的带宽;所有使用率超过设置值(配置文件中可配)时会红色加粗显示。点击服务器IP,可以查看更详细的服务器信息,如:CPU型号、磁盘号、网卡。
端口监控列表页
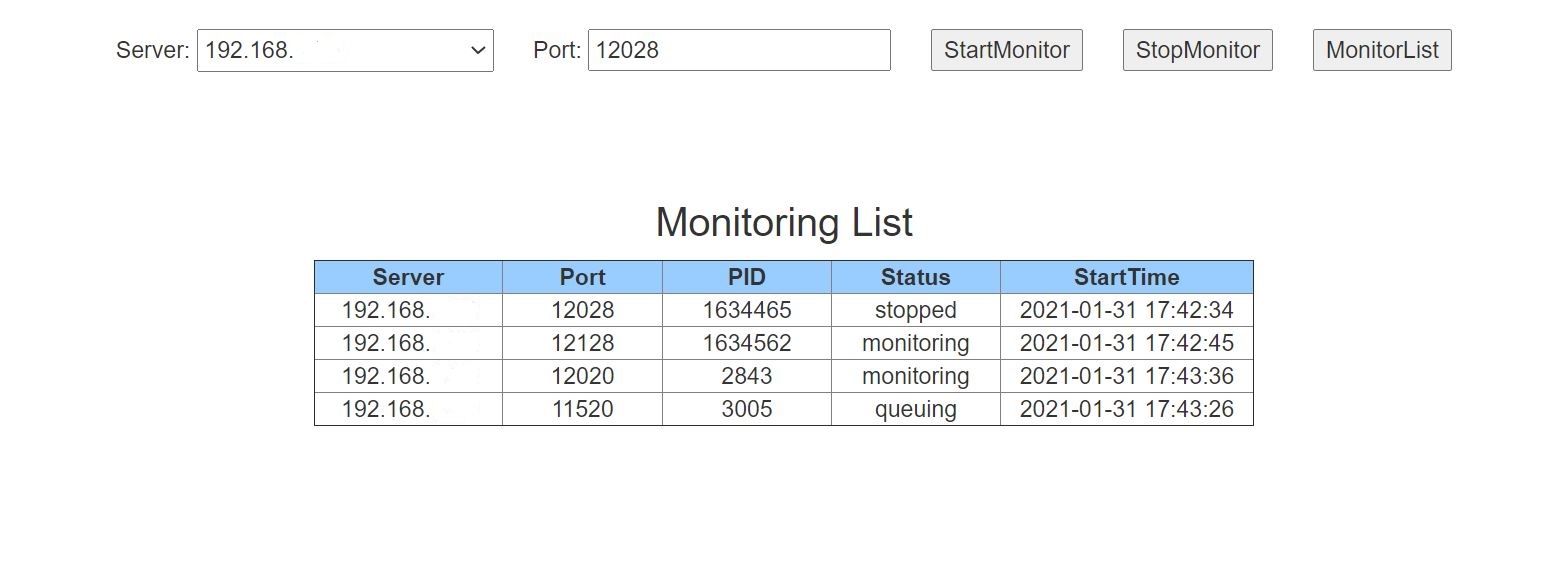
监控列表页展示了当前监控的端口信息,端口信息分别是服务器 IP、端口号、进程号、监控状态、开始监控时间。监控状态有 3 种状态:监控中、已停止、排队中。
监控列表页默认展示所有服务器监控的端口,只有点击 MonitorList 按钮才会展示当前服务器上监控的端口信息。如需开始监控端口,则先选择服务器,然后输入端口,最后点击 StartMonitor 按钮;如需停止监控端口,则先选择服务器,然后输入端口,最后点击 StopMonitor 按钮。
可视化页面
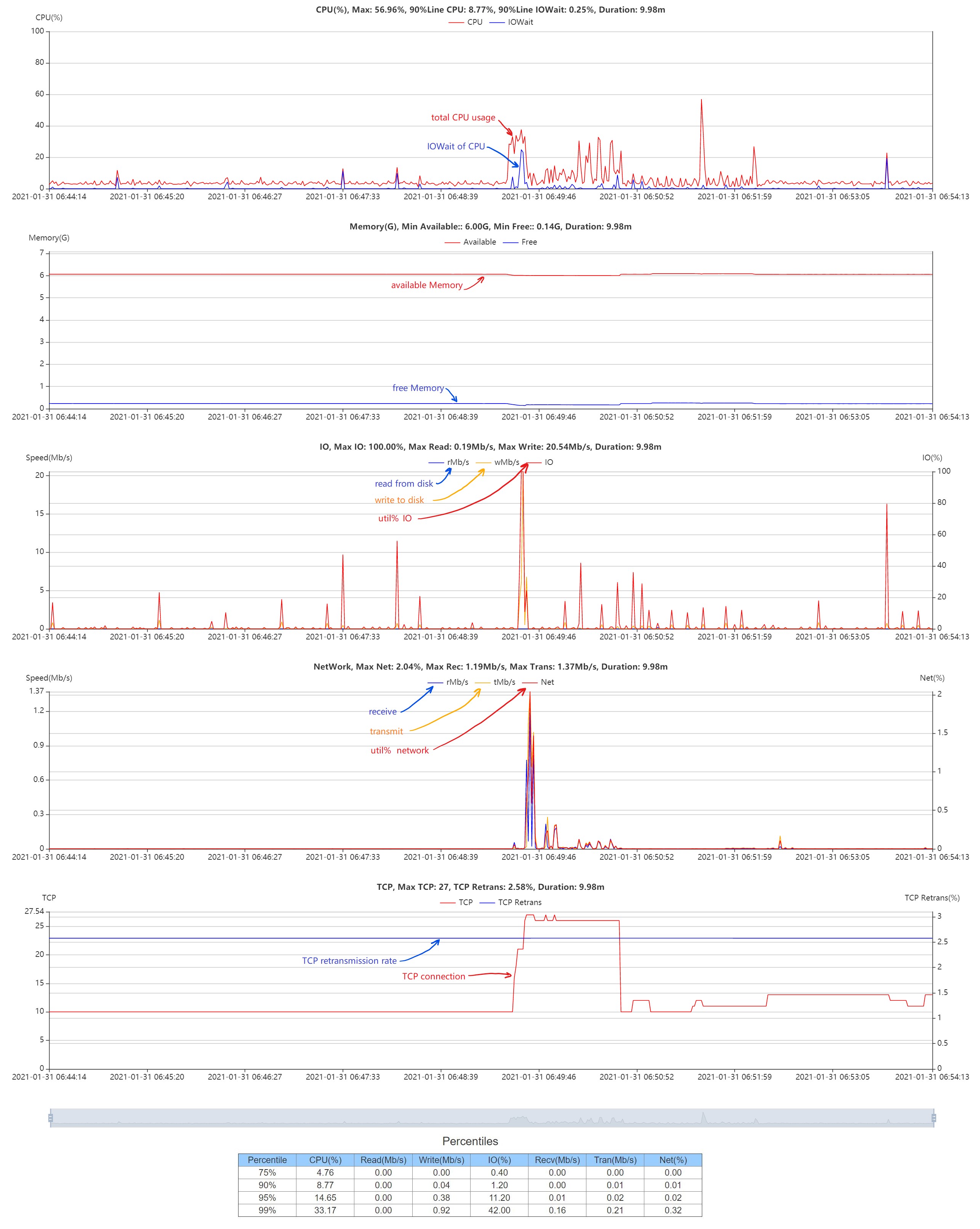
可视化页面主要对监控的数据进行可视化,可视化的图中的数据可交互。为了确保准确性,可视化数据时未做任何曲线拟合处理。
可视化数据时的筛选项:服务器 IP、数据来源类型(系统数据或端口数据)、端口号(如果数据来源类型选择系统数据,则不需要端口号)、磁盘号、可视化数据的时间段(开始时间和结束时间)。
查看系统监控数据
如果选择的数据来源类型是系统:
第一个图是服务器总的 CPU 使用率和 iowait。总的 CPU 使用率可以看出服务器的整体负载。
第二个图是服务器的 CPU load,分别是最近 1 分钟、5分钟和 15 分钟的 CPU Load。
第三个图是服务器的可用内存和剩余内存。可用内存和剩余内存的差值就是服务器的缓存使用大小。该图数据仅是物理内存,不包括虚拟内存。
第四个图是服务器的磁盘读写速率和磁盘IO。这里展示的是指定磁盘的数据,可以看出当前磁盘是否存在瓶颈。
第五个图是服务器的网卡接收和发送速率,以及网络带宽使用率。可以看出服务器是否存在网络瓶颈。
第六个图是服务器的 TCP 的数量和 TCP 的重传数。TCP 重传数可以看出当前网络环境是否稳定。
最后的表格统计的是 CPU 使用率、磁盘IO、网卡使用率的百分位数。主要有 4 个百分位:75%、90%、95%、99%。为什么要统计百分位数?例如看 CPU 使用率,不能看平均值,也不能看最大值,更不能看最小值,这些值都不能准确的反映出 CPU 在一段时间内的使用率,因此要使用百分位数来量化 CPU 在一段时间内的使用率,通常选择的百分位是 90%,也可根据实际需求选择其他的百分位。
查看端口监控数据
如果选择的数据来源类型是端口:
第一个图是进程(端口对应的进程)的 CPU 使用率和用于上下文切换的 CPU 使用率。
第二个图是进程占用的内存。如果这个进程是 java 服务,则还会展示 JVM 内存变化情况,从 JVM 的内存变化可以看出 java 服务是否会出现内存溢出问题。
第三个图是进程读写磁盘的数据,可以直接看出进程是否在大量使用磁盘。
第四个图是端口的 TCP 数据,包括建立的 TCP 连接数、处于 TIME_WAIT 状态的 TCP 数、处于 CLOSE_WAIT 状态的 TCP 数。重点关注处于 TIME_WAIT 和 CLOSE_WAIT 的 TCP 数是否存在异常。
最后的一个表格统计的也是 CPU 使用率,磁盘IO,网卡使用率的百分位数。如果是 java 服务,还会有一个表格展示的是垃圾回收的数据,特别是 FGC,需要重点关注。
重点关注的配置项
1、host:是本机的 IP 地址,一般情况下都会自动获取到,如果服务器有多个网卡,且使用的不是第一张网卡,那么自动获取的 IP 可能不正确,可通过 hostname -I 命令查看第一个 IP 是不是本机 IP,如果不是,需要手动配置 host。
2、server_context:是浏览器访问的 url 的 prefix,请按要求配置你想配置的任意名字,不要再问我为什么页面报 404 了。
3、InfluxDB 相关的配置,需要提前部署并配置好 InfluxDB。
Agent(执行器)
Agent 主要用于执行监控任务,采集并存储数据。数据采集主要是使用 sysstat 工具,使用命令是 iostat 和 pidstat,采集的数据未做任何处理直接存入数据库,数据准确度取决于 sysstat。
Agent 启动过程
启动 Agent 时,首先会检查 sysstat 版本,当前测试通过的版本是 v12.4.0,如果使用 12 之前的版本,会导致采集的数据不准确。所以建议手动安装 sysstat,安装过程非常简单(不会的话请自行百度),安装完成后,输入 iostat -V 和 pidstat -V 命令查看版本号,如果版本号显示不正确,请将安装目录下的 iostat 和 pidstat 软连接到 /usr/bin/iostat 和 /usr/bin/pidstat 目录下,然后再查看版本号。
sysstat 版本号检查通过后,做了以下动作:
1、启动服务,开始监听端口
2、查询服务器的一些基本数据:服务器IP、系统版本、CPU核数、CPU型号、内存大小、磁盘大小、磁盘号、网卡、网络带宽
3、初始化队列,启动线程池,从队列中获取任务并执行
4、将监控整个服务器的任务放入队列中
5、将服务注册任务和定时清理端口任务放入队列中
6、Agent 每隔 8s 注册自己的状态,待 Agent 注册成功后,就可以在 Server 的前端页面中看到这个服务器信息了
在 Server 前端页面,点击 StartMonitor 按钮后,Agent 做了如下动作:
1、检查 Agent 注册状态,防止 Agent 已掉线而前端页面未刷新
2、根据端口号查询进程号,判断端口是否处于监听状态
3、检查是否是 java 服务,非 java 服务就不用执行多余的命令,节省资源
4、将监控端口的任务放入队列中
在 Server 前端页面,点击 StopMonitor 按钮后,Agent 直接将该端口的状态修改为已停止,通过状态检查,会直接跳出循环停止监控,释放线程。
Server 前端页面展示的监控状态有 3 种状态:监控中(monitoring)、已停止(stopped)、排队中(queuing)。处于监控中状态的端口的数量受线程池大小的影响,线程池大小通过配置文件可配。如果线程池设置为 2,当开始监控第 3 个端口时,该端口就会处于排队状态;此时前两个端口中的任一端口停止监控,第 3 个端口会自动开始监控,进入监控状态。
建议实际监控端口时,不要同时监控太多的端口。同时监控的端口越多,监控本身占用的系统资源也就越多,建议及时停止监控不需要监控的端口。
Agent 启动成功后,可以查看服务器的基本信息,如下图:

服务注册
Agent 启动成功后,会每隔 8s 向 Server(服务端)注册自己信息,注册信息包括:服务器 IP、当前 CPU 使用率、当前内存使用率、当前磁盘使用率。注册成功后,Server(服务端)会更新 Agent 的数据,同时更新 Agent 的注册时间。
Server(服务端)启动成功后,会每隔 12s 检查所有 Agent 的注册状态,如果注册时间未更新,则会将对应的 Agent 踢下线。
Server 和 Agent 没有绝对的依赖关系,Server 挂了不会影响 Agent 的运行,仍然可以正常监控数据,如果 Server 重启后,Agent 还会自动注册;Agent 挂了不会影响 Server 的运行,仍然可以正常查看其他 Agent 的监控数据。
数据采集
通过执行 iostat、pidstat 等命令采集数据,数据采集频率可在配置文件中配置,理论最高可达 1次/s,实际上由于磁盘IO数据的采集频率最高是 1次/s,再加上程序运行和数据写入的时间,实际数据采集最高的频率是 0.85次/s 左右。
建议实际监控时,请根据实际需求设置数据采样频率,监控整个服务器的频率和监控端口的频率可以分开设置。数据采样频率设置越高,监控本身占用的系统资源也就越多。
端口停止
正常情况下,端口处于监听状态,那么执行监控命令时就不会报错。如果端口由于某种原因停止,则会根据配置进行不同的处理:
非运维监控配置:端口停止后,会每隔指定的时间(可配置)检查端口状态,每检查一次会计次,达到指定的次数(可配置)后会将端口的监控状态设置为已停止,然后停止监控该端口,释放线程。
为什么要等这么长时间才停止呢?这是考虑到我们会经常重启端口,当端口重启后会自动重新开始监控。如果端口停止了就也停止监控,端口重启后还需要手动再次开始监控,这个操作很不友好。
运维监控配置:端口停止后,会每隔指定的时间(可配置)检查端口状态,每检查一次会计次,达到指定的次数(可配置)后会将端口的监控状态设置为已停止,启动子线程发送邮件提醒(如果配置提醒),然后停止监控该端口,释放线程。
上述两种配置的处理逻辑基本一致,区别是次数不一样。这两种配置是互斥的,只允许选择其中的一种。
清理已停止监控的端口
考虑到服务器压力,尽量监控需要监控的端口,暂不需要监控的端口可以先停掉,如果停止监控后又想看监控数据,那么端口停止后就不能立即把端口的监控记录删除,故设计成每天定时清理一次,定时时间可配置。
如果一个端口已经停止监控好几天了,仍想看监控数据怎么办,很简单,再开始监控一次就好了。清理端口监控记录不会清理数据库中的数据,只要数据库中的数据没有过期,就仍然可以查看。
邮件提醒
Agent 配置文件中可配异常数据是否发送邮件提醒。异常数据项包括:CPU 使用率、内存使用率、端口异常停止、FGC 频率。如配置了邮件提醒,当数据异常时,会重新开启子线程用于将异常信息发送到 Server 端,Server 再根据配置的邮箱信息将异常数据提醒发送到指定的收件人。
快速部署
首先,选择一台服务器,准备好 Python 运行环境,安装依赖包,然后运行程序,如果正常运行,说明环境已经调试完成。
然后,使用 pyinstaller 工具进行打包,完成 Agent 打包后,修改配置文件。
最后将打包生成的可执行文件和配置文件拷贝到其他服务器上,直接执行启动命令即可完成部署。
注意:在 X64 架构的 Ubuntu 系统上打包的可执行文件只能在 X64 架构的 Ubuntu 系统上运行,如需要在其他系统版本和处理器架构的服务器上执行,需要在对应的系统版本和处理器架构的服务器上进行打包。